- https://istio.io/docs/concepts/what-is-istio/overview
- https://www.jaegertracing.io/docs/
- https://www.ansible.com/
- https://thrift.apache.org/
- https://developers.google.com/protocol-buffers/
- https://github.com/infinispan/protostream
- https://nodered.org/
- https://kafka.apache.org/
- https://www.thethingsnetwork.org/community/winterthur/
- https://www.thethingsnetwork.org/docs/devices/registration.html
- https://www.thethingsnetwork.org/docs/devices/uno/
- http://zeppelin.apache.org/
- http://jupyter.org/
Dienstag, 26. Juni 2018
Note to myself: trending Technologies
Note to myself: (more or less) trending Technologies, die ich mir grad merken will - ziemlich zusammenhangslos:
Dienstag, 5. Juli 2016
MS SQL und PostgreSQL: Beispiele von Fehlermeldungen.
Ein wunderschönes Beispiel von zwei Fehlermeldungen für genau den gleichen Fehler:
Welcher ist von PostgreSQL, welcher von Microsoft SQL? ;-)
Ps: folgende zwei Dinge, die in PostgreSQL normal sind, gehen in MS SQL nicht:
insert into employee_language (employee_id,languages_iso) VALUES ('958980','fr');
Error: The INSERT statement conflicted with the FOREIGN KEY constraint "FK_employee". The conflict occurred in database "AgentAndAgency", table "dbo.employee", column 'id'.
SQLState: 23000
ErrorCode: 547
Error: FEHLER: Einfügen oder Aktualisieren in Tabelle „employee_language“ verletzt Fremdschlüssel-Constraint „FK_employee“
Detail: Schlüssel (employee_id)=(958980) ist nicht in Tabelle „employee“ vorhanden.
SQLState: 23503
ErrorCode: 0
Welcher ist von PostgreSQL, welcher von Microsoft SQL? ;-)
Ps: folgende zwei Dinge, die in PostgreSQL normal sind, gehen in MS SQL nicht:
- select distinct geht nicht, wenn ein Datenfeld ein image ist
- natural join geht nicht
- UTF-8 Text geht mit varchar nicht - es braucht nvarchar und ein merkwürdiges N vor jedem Text: N’русский’ - und dann noch eine Annotation im JPA.
Dienstag, 21. Juni 2016
Continuous Delivery - offene Fragen und einige Antworten.
in meiner "nebenamtlichen Tätigkeit" als DevOps Engineer oder wie auch immer das heisst, bleiben immer wieder folgende offene Fragen an mir hängen. Ich schreibe sie hier auf - für mich selber - und als Diskussionsgrundlage.
Das Setup ist: Jekins, Jira, git mit Bitbucket, nexus
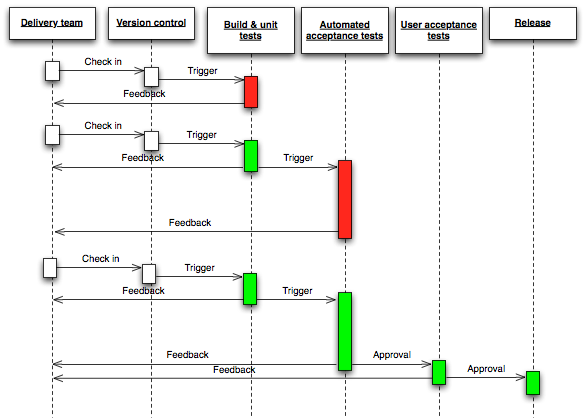
Das Setup ist: Jekins, Jira, git mit Bitbucket, nexus
Developement Pipeline und Release-Management
Features werden innerhalb eines Scrum-Prozesses von Entwicklern ganz normal auf einem feature-Branch entwickelt. Sie passieren diverse Schwellen im den Developement-Pipeline:

Quelle: http://fabric8.io/guide/cdelivery.html
...und generieren dort feedback. Je nach Feedback dürfen die features nicht in der Pipeline weitergehen.
Die Frage ist nun:
- wie kann ich verhindern, dass ein release gemacht wird, wenn ein feature einen roten Feedback hat? (z.B. Integraions-Tests müssen grün sein, bevor ein Release läuft. Nichts neues ist gemergt) (Antwort: Pre-Commit Verification, Infrastruktur fehlt bei uns.)
- wenn die Pipeline grün ist: wie kann ich verhindern, dass unterdessen nichts neues auf den Integrations-Branch (oder Trunk) eingecheckt wurde, bevor ich den release gemacht habe? (wer überwacht das?) (Das ist ok - Pipeline baut Artefakte, welche geprüft sind).
- wie kann ich in Jira anzeigen, welche Schwellen ein Feature schon passiert hat?
- wie kann ich in Jira anzeigen, welches Feature auf welchem Stage in welchem Release installiert ist?
- wenn ich dann einen Release mache: wie kommuniziert Jenkins dem Jira, welches feature in welchem Release gelandet ist? (automatische Release-Notes - Infrastruktur fehlt)
- was ist ein Release: ein Release im Sinn von Scrum nach ein paar Sprints - oder ein Release im Sinn von maven, wo kein -SNAPSHOT in der Version steht? (Jira-Versionen und Maven-Release-Versionen müssen synchron sein.)
Branching-Modell: trunk-based Development
Immer wieder Dikussionen entstehen mit dem Unterschied von Modellen wie gitflow und trunk-based development.
- Genügt ein Hauptbranch, der immer "grün" ist? Oder braucht es für jeden Releease, Bugfix etc. einen eigenen Branch, mit dem Rattenschwanz von Merg-Tasks? (ja!)
- Genügt ein Tag für einen Release? (ja!)
Auch immer wieder für Verwirrung sorgt: was wird auf Produktion installiert? Ein bestimmer Release (ein Artefakt in nexus), oder ein bestimmter Branch im git? (Bei unserem Setup ein Artefakt auf Nexus, das auf dem Hauptbranch getagt ist).
Antwort, update: Ich fahre momenten mit einem Mix von Trunk-Based-Development und pre-merge-verification sehr gut. Wichtig ist: "keep your main branch green",
Konkret: Die Entwickler sind dafür verantwortlich, auf ihrer lokalen Maschine einen Rebase oder merge from main-branch ihres Entwicklungs-Branch zu machen, und ihn local zu testen (jUnit und Selenium.) Danach wird ein Pull-Request erstellt, der von anderen Teammitgliedern manuell geprüft wird. Erst dann wird auf den Main-Branch gemergt, welcher dann sofort vom Jenkins-CI-Server integriert, auf DEV installiert und getestet wird. Mit diesem Ansatz erreichen wir eine sehr gute Code-Qualität, obwohl die Qualität der Selenium-Tests schlecht ist. Und als Nebeneffekt ist der Know-How-Transfer im Team besser.
Siehe dazu auch folgender Artikel (Vortrag an der ConDelivery in Mannheim):
Antwort, update: Ich fahre momenten mit einem Mix von Trunk-Based-Development und pre-merge-verification sehr gut. Wichtig ist: "keep your main branch green",
Konkret: Die Entwickler sind dafür verantwortlich, auf ihrer lokalen Maschine einen Rebase oder merge from main-branch ihres Entwicklungs-Branch zu machen, und ihn local zu testen (jUnit und Selenium.) Danach wird ein Pull-Request erstellt, der von anderen Teammitgliedern manuell geprüft wird. Erst dann wird auf den Main-Branch gemergt, welcher dann sofort vom Jenkins-CI-Server integriert, auf DEV installiert und getestet wird. Mit diesem Ansatz erreichen wir eine sehr gute Code-Qualität, obwohl die Qualität der Selenium-Tests schlecht ist. Und als Nebeneffekt ist der Know-How-Transfer im Team besser.
Siehe dazu auch folgender Artikel (Vortrag an der ConDelivery in Mannheim):
...die Frageliste ist nicht abgeschlossen, und wird in nächste Zeit überarbeitet werden müssen...
Donnerstag, 16. Juni 2016
dans les nuages
note to myself: vernebelt um die vielen neuen schönen Dinge, die plötzlich wie Pilze aus dem Boden schiessen, oder besser zum Wetter passend: wie Gewitterwolken am Himmel erscheinen.
Eine lose Ansammlung von Werkzeugen, Artikeln etc. über kontinuierliche Auslieferung, alternative Datenquellen, Paradigmen, die es Wert sind, zum lesen aufzubewahren: sozusagen ein Rundumschlag von interessanten Themen, die alle nichts mit GUI zu tun haben.
JBoss etc.
http://www.schabell.org/2016/06/howto-get-appdev-on-with-jboss-travel-agnecy-in-cloud-video.html
https://www.push2.cloud
https://www.cloudfoundry.org/learn/features/
https://www.chef.io/blog/2016/06/14/introducing-habitat/
https://www.habitat.sh
https://www.chef.io
https://puppet.com
http://fabric8.io
Teiid mit OData
https://developer.jboss.org/wiki/ProducingAndConsumingODataInTeiidAndTeiidDesigner
http://www.confluent.io/product
http://blog.christianposta.com/microservices/why-microservices-should-be-event-driven-autonomy-vs-authority/
https://www.particle.io
http://www.mikrocontroller.net/articles/STM32
http://www.eclipse.org/kura/
http://developers.redhat.com/blog/2016/11/17/getting-started-with-apache-camel-and-the-internet-of-things/?sc_cid=701600000011zW0AAI
Eine lose Ansammlung von Werkzeugen, Artikeln etc. über kontinuierliche Auslieferung, alternative Datenquellen, Paradigmen, die es Wert sind, zum lesen aufzubewahren: sozusagen ein Rundumschlag von interessanten Themen, die alle nichts mit GUI zu tun haben.
Cloud
JBoss etc.
http://www.schabell.org/2016/06/howto-get-appdev-on-with-jboss-travel-agnecy-in-cloud-video.html
https://www.push2.cloud
https://www.cloudfoundry.org/learn/features/
https://www.chef.io/blog/2016/06/14/introducing-habitat/
https://www.habitat.sh
https://www.chef.io
https://puppet.com
http://fabric8.io
Data
Teiid mit OData
https://developer.jboss.org/wiki/ProducingAndConsumingODataInTeiidAndTeiidDesigner
http://www.confluent.io/product
Microservices
http://blog.christianposta.com/microservices/why-microservices-should-be-event-driven-autonomy-vs-authority/
IoT
https://www.particle.io
http://www.mikrocontroller.net/articles/STM32
http://www.eclipse.org/kura/
http://developers.redhat.com/blog/2016/11/17/getting-started-with-apache-camel-and-the-internet-of-things/?sc_cid=701600000011zW0AAI
Montag, 2. Mai 2016
Continuous Delivery: beyond Jenkins
...zwei alternative Deliver-Server, die mir über den Weg gelaufen sind - und weiter gehen als Jenkins 2.0 und Bamboo:
https://concourse.ci/index.html
und:
https://www.go.cd/
https://concourse.ci/index.html
und:
https://www.go.cd/
3-Wege-Merge
Einfacher, guter Artikel über die Sache mit dem 3-Wege-Merge:
http://www.drdobbs.com/tools/three-way-merging-a-look-under-the-hood/240164902
http://www.drdobbs.com/tools/three-way-merging-a-look-under-the-hood/240164902
Freitag, 1. April 2016
Eschenberg-Loipe: Abrechnung mit GIS-iPhone-App
neuer Nebenjob: im Zusammenhang mit dem heute vorgestellten Langlauf-Projekt auf dem Eschenberg (Landbote: http://www.landbote.ch/winterthur/standard/kunstschnee-fuer-die-eschenbergloipe/story/26635955 ) konnte ich einen neuen Auftrag einfangen:
Ich entwickle zusammen mit einem Spezialisten für künstliche Intelligenz eine kleine iPhone-App (in Auftrags-Basis), welche die Abrechnung für die Eintritte zur Langlauf-Loipe automatisch berechnet und direkt mit dem Steueramt der Stadt Winterthur verrechnet. (Verursachergerechte Gebühren). Die App wird ca. folgende Haupt-Features haben:

Ich entwickle zusammen mit einem Spezialisten für künstliche Intelligenz eine kleine iPhone-App (in Auftrags-Basis), welche die Abrechnung für die Eintritte zur Langlauf-Loipe automatisch berechnet und direkt mit dem Steueramt der Stadt Winterthur verrechnet. (Verursachergerechte Gebühren). Die App wird ca. folgende Haupt-Features haben:
- GIS (Fencing etc.) erkennt automatisch, ob sich jemand auf der Loipe befindet
- Gewegungsanalyse merkt, ob jemand Langlauf fährt oder nur spaziert
- Die Daten werden in Apple Health-Kit eingespiesen.
Optional werden die Bewegungsdaten an Gesundheistorganisationen verkauft werden, sodass der Eintrittpspreis zur Loipe noch billiger wird.
Für die Entwicklung der App brauche ich Unterstützung von iPhone-Entwicklern - wer Zeit und Lust hat, kann sich heute 1. April bei mir melden. Der erste bekommt ein Bier.

Abonnieren
Kommentare (Atom)